code

share



In Sections 8.4, 9.4, and 10.3 we have seen how feature scaling via standard normalization - i.e., by subtracting off the mean of each input feature and dividing off its standard deviation - significantly improves the topology of a supervised learning cost function enabling much more rapid minimization via e.g., gradient descent. In this Section we describe how PCA is used to perform an advanced form of standard normalization - commonly called PCA sphereing (it also referred to as whitening). With this variation on standard normalization we use PCA to rotate the mean-centered dataset so that its largest orthogonal directions of variance allign with the coordinate axes prior to scaling each input by its standard deviation. This typically allows us to better compactify the data, resulting in a cost function whose contours are even more 'circular' than that provided by standard normalization and thus makes supervised cost functions even easier to optimize.
Using the same notation as in the previous Section we denote by $\mathbf{x}_p$ the $p^{th}$ input of $N$ dimensions belonging to some dataset of $P$ points. By stacking these together column-wise we create our $N\times P$ data matrix $\mathbf{X}$. We then denote $\frac{1}{P}\mathbf{X}\mathbf{X}^T + \lambda \mathbf{I}_{N\times N}$ the regularized covariance matrix of this data and $\frac{1}{P}\mathbf{X}^{\,} \mathbf{X}^T +\lambda \mathbf{I}_{N\times N}= \mathbf{V}^{\,}\mathbf{D}^{\,}\mathbf{V}^T$ its eigenvalue/vector decomposition.
Now remember that when performing PCA we first mean-center our dataset - that is we subtract off the mean of each coordinate (note how this is the first step in the standard normalization scheme as well). We then aim to represent each of our mean-centered datapoints datapoint $\mathbf{x}_p$ by $\mathbf{w}_p = \mathbf{V}_{\,}^T\mathbf{x}_p^{\,}$. In the space spanned by the principal components we can represent the entire set of transformed mean-centered data as
\begin{equation} \text{(PCA transformed data)}\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\mathbf{W} = \mathbf{V}^T\mathbf{X}^{\,}. \end{equation}With our data not rotated so that its largest orthogonal directions of variacne align with the coordinate axes, to sphere the data we simply divide off the standard deviation along each coordinate of the PCA-transformed (mean-centered) data $\mathbf{W}$.
In other words, PCA-sphereing is simply the standard normalization scheme we have seen before (see e.g., Sections 8.4, 9.4 and 10.3) with a single step inserted in between mean centering and the dividing off of standard deviations: in between these two steps we rotate the data using PCA. By rotating the data prior to scaling we can typically shrink the space consumed by the data considerably more than standard normalization, while simultaneously making any associated cost function considerably easier to minimize properly.
PCA-sphereing is simply the standard normalization scheme we have seen before (see e.g., Sections 8.4, 9.4 and 10.3) with a single step inserted in between mean centering and the dividing off of standard deviations: in between these two steps we rotate the data using PCA. By rotating the data prior to scaling we can typically shrink the space consumed by the data considerably more than standard normalization, while simultaneously making any associated cost function considerably easier to minimize properly.
In the Figure below we show a generic comparison of how standard normalization and PCA sphereing affect a prototypical dataset, and its associated cost function. Because PCA sphereing first rotates the data prior to scaling it typically results in more compact transformed data, and a transformed cost function with more 'circular' contours (which is easier to minimize via gradient descent).
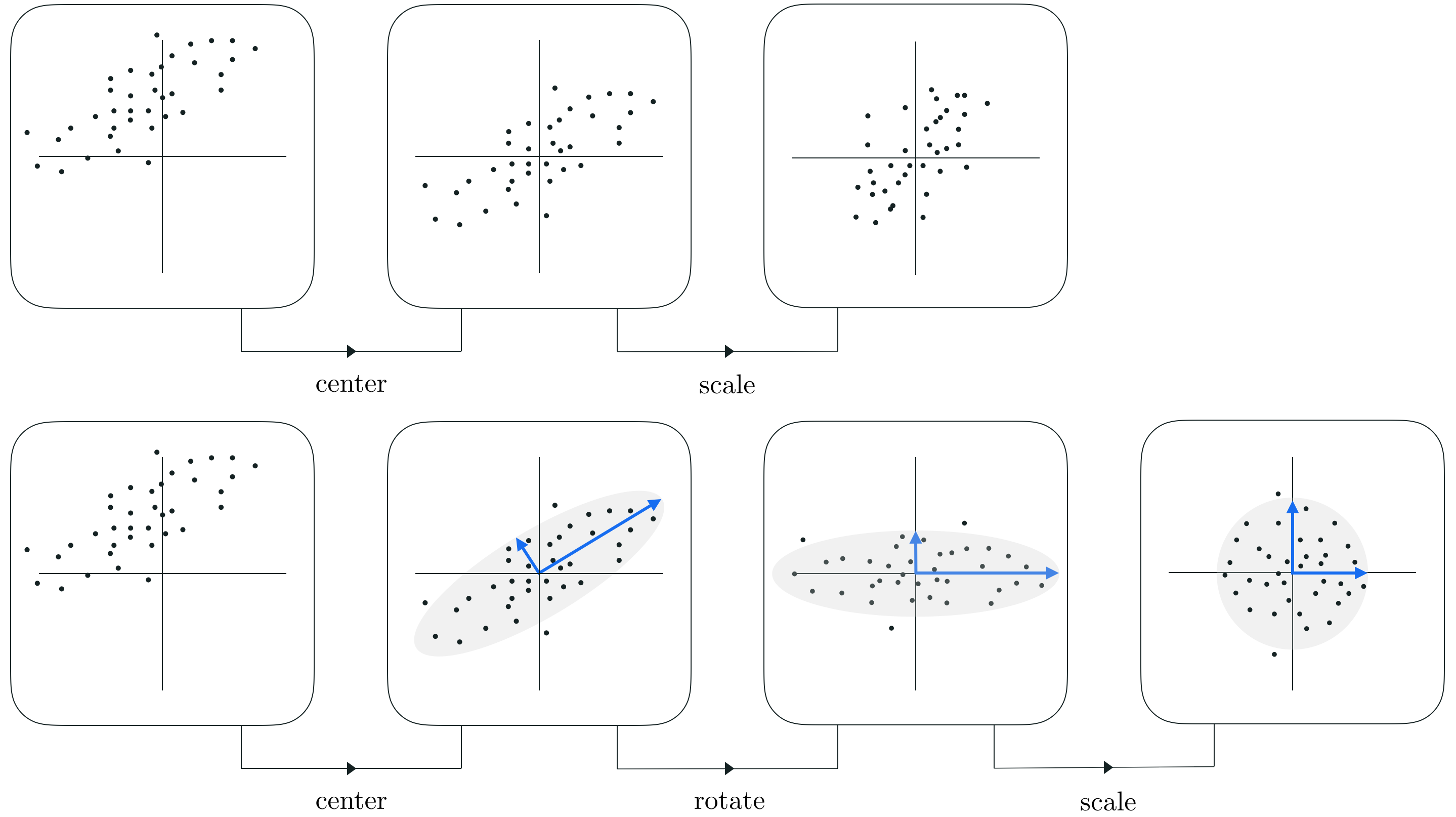

More formally if the standard normalalization scheme applied to a single datapoint $\mathbf{x}_p$ can be written in two steps as
Standard normalization scheme:
A Python implementation is given below - notice it returns a normalizer function that normalizes any input according to the statistics of $\mathbf{X}$.
# standard normalization function
def standard_normalizer(x):
# compute the mean and standard deviation of the input
x_means = np.mean(x,axis = 1)[:,np.newaxis]
x_stds = np.std(x,axis = 1)[:,np.newaxis]
# create standard normalizer function
normalizer = lambda data: (data - x_means)/x_stds
# create inverse standard normalizer
inverse_normalizer = lambda data: data*x_stds + x_means
# return normalizer
return normalizer,inverse_normalizer
The PCA-sphereing scheme can be then be written in three highly related steps as follows
PCA-sphereing scheme:
Below we provide a Python implementation of PCA-sphereing. The input to the function PCA_sphereing is a data matrix x, and it returns two functions normalizer - that one can use to perform sperehing on any input (both training and future test points) - and inverse_normalizer that can be used to reverse the operation. One can notice that the only difference between how the method is detailed above and the actual implementation is implementing step 3 we divide off the square root of the eigenvalues of the regularized covariance matrix. This is done for computational efficiency's sake since - as we discuss in the next Section - the $n^{th}$ eigenvalue $d_n$ actually equals the variance of the PCA-transformed data i.e., $d_n = \sigma_n^2$, so dividing off its square root is equal to dividing off by the standard deviation.
# compute eigendecomposition of data covariance matrix for PCA transformation
def PCA(x,**kwargs):
# regularization parameter for numerical stability
lam = 10**(-7)
if 'lam' in kwargs:
lam = kwargs['lam']
# create the correlation matrix
P = float(x.shape[1])
Cov = 1/P*np.dot(x,x.T) + lam*np.eye(x.shape[0])
# use numpy function to compute eigenvalues / vectors of correlation matrix
d,V = np.linalg.eigh(Cov)
return d,V
# PCA-sphereing - use PCA to normalize input features
def PCA_sphereing(x,**kwargs):
# Step 1: mean-center the data
x_means = np.mean(x,axis = 1)[:,np.newaxis]
x_centered = x - x_means
# Step 2: compute pca transform on mean-centered data
d,V = PCA(x_centered,**kwargs)
# Step 3: divide off standard deviation of each (transformed) input,
# which are equal to the returned eigenvalues in 'd'.
stds = (d[:,np.newaxis])**(0.5)
normalizer = lambda data: np.dot(V.T,data - x_means)/stds
# create inverse normalizer
inverse_normalizer = lambda data: np.dot(V,data*stds) + x_means
# return normalizer
return normalizer,inverse_normalizer
With our sphereing implementation defined we can try PCA sphereing out on a dataset. Here we will use the simple dataset shown in e.g., example 2 of the previous Section. The next cell runs the sphereing code above, and then the cell after plots comparisons of the a) the original data (left panel), b) the standard normalized data (middle panel), and c) the PCA sphered data (right panel). Here sphereing drastically improved the distribution of the original dataset, which (if this were a supervised learning dataset) will drastically improve our ability to quickly tune the parameters of a supervised model via gradient / coordinate descent.

In this and the following example we compare runs of gradient descent on various real datasets using a) the original input, b) standard normalized input, and c) PCA sphered input. The Python function can be used to loop over three gradient descent runs using a single cost function with each version of the data loaded in. Three steplength parameter inputs allow one to adjust and compare steplength choices for each run.
As we saw when comparing standard normalization to original input in Sections 8.4, 9.4, and 10.3 we will typically find that a substantially larger steplength value can be used when comparing a run on original data to one on standard normalized data, and likewise when comparing a run on standard normalized data to one in which the input was first PCA sphered. The intuition behind why this is possible - first detailed in Section 8.4.3 - is that PCA sphereing tends to make the contours of a cost function even more 'circular' than standard normalization, and the more circular a cost function's contours become the larger the steplength one can use because the gradient descent direction aligns more closely with the direction one must travel in to reach a true global minimum of a cost function.
As our first example we compare a runs of gradient descent using a real $N = 8$ input breast cancer dataset, a description of which you can find here). Below we load in the data and run the function above (outputting results on the original, standard normalized, and PCA sphered input).
Now we run the comparison module. For each run we found the largest steplength of the form $\alpha = 10^{-\gamma}$ for an integer $\gamma$ that produced adequate convergence. Notice that in comparing these values below, that here we can use at least an order of magnitude larger steplength when going from the original, to standard normalized, to PCA sphered input.
With the runs complete we can now plot the cost and misclassification histories for each run to visually examine and compare the progress of each run. Examining the plot below we can see how both normalization schemes result in runs that converge much more rapidly than applying gradient descent to the raw data. Furthermore, the run on PCA sphered input converges more rapidly than the run on standard normalized input. We can examine this more closely by plotting the corresponding histories of just these two runs - which we do below.

Plotting the histories of just the runs on standard normalized and PCA sphered inputs, as is shown below, we can see just how much faster the run on the PCA sphered data converges than the corresponding run on the standard normalized data. Examining the misclassification history in particular we can see that the PCA sphered data converges almost immediately.

Next we illustrate a run on each type of input using $10,000$ handwritten digits from the MNIST dataset - consisting of hand written digits between 0 and 9. These images have been contrast normalized, a common pre-processing technique for image based data we discuss in Chapter 16.
We pick steplength values precisely as done in the previous dataset, and again find that we pick much larger values when comparing runs on the original to that of the standard normalized input, and this to the PCA sphered input.
Plotting the resulting cost function histories we can see how the run on standard normalized data converges rapidly in comparison to the raw data, and how the run on PCA sphered data converges even more rapidly still.

Here we briefly describe how one can write the PCA-sphereing scheme more elegantly by leveraging our understanding of eigenvalue/vector decompositions. This will result in precisely the same PCA-sphereing scheme we have seen previously, only written in a prettier / more elegant way mathematically speaking. This also helps shed some light on the theoretical aspects of this normalization scheme. However in wading through the mathematical details be sure not to lose the 'big picture' communicated previously: that PCA-sphereing is simply an extension of standard normalization where a PCA rotation is applied after mean centering and before dividing off standard deviations.
Now, if we so choose we can express steps 2 and 3 of PCA-sphereing in a more mathematically elegant way using the eigenvalues of the regularized covariance matrix. The Raleigh quotient definition (see e.g., the previous Section) of the $n^{th}$ eigenvalue $d_n$ of this matrix states that numerically speaking
\begin{equation} d_n = \frac{1}{P}\mathbf{v}_n \mathbf{X}_{\,}^{\,} \mathbf{X}_{\,}^T \mathbf{v}_n \end{equation}where $\mathbf{v}_n$ is the $n^{th}$ and corresponding eigenvector. Now in terms of our PCA transformed data this is equivalently written as
\begin{equation} d_n = \frac{1}{P}\left\Vert \mathbf{v}_n^T \mathbf{X} \right \Vert_2^2 = {\frac{1}{P}\sum_{p=1}^{P}\left(w_{p,n}\right)^2} \end{equation}or in other words, it is the variance along the $n^{th}$ axis of the PCA-transformed data. Since the final step of PCA-sphereing has us divide off the standard deviation along each axis of the transformed data we can then write it equivalently in terms of the eigenvalues as
3). (divide off std) for each $n$ replace $w_{p,n} \longleftarrow \frac{w_{p,n}}{d_n^{1/_2}}$ where $d_n^{1/_2}$ is the square root of the $n^{th}$ eigenvalue of the regularized covariance matrix
Denoting $\mathbf{D}^{-1/_2}$ as the diagonal matrix whose $n^{th}$ diagonal element is $\frac{1}{d_n^{1/_2}}$, we can then (after mean-centering the data) express steps 2 and 3 of the PCA-sphereing algorithm very nicely as
\begin{equation} \text{(cleverly-written PCA-sphered data)}\,\,\,\,\,\,\,\,\, \mathbf{S}^{\,} = \mathbf{D}^{-^1/_2}\mathbf{W}^{\,} = \mathbf{D}^{-^1/_2}\mathbf{V}^T\mathbf{X}^{\,}. \end{equation}While expressing PCA-sphereing in may seem largely cosmetic, notice that in the actual implementation (provided above) it is indeed computationally advantageous to simply use the eigenvalues in step 3 of the method (instead of re-computing the standard deviations along each transformed input axis) since we compute them anyway in performing PCA in step 2.
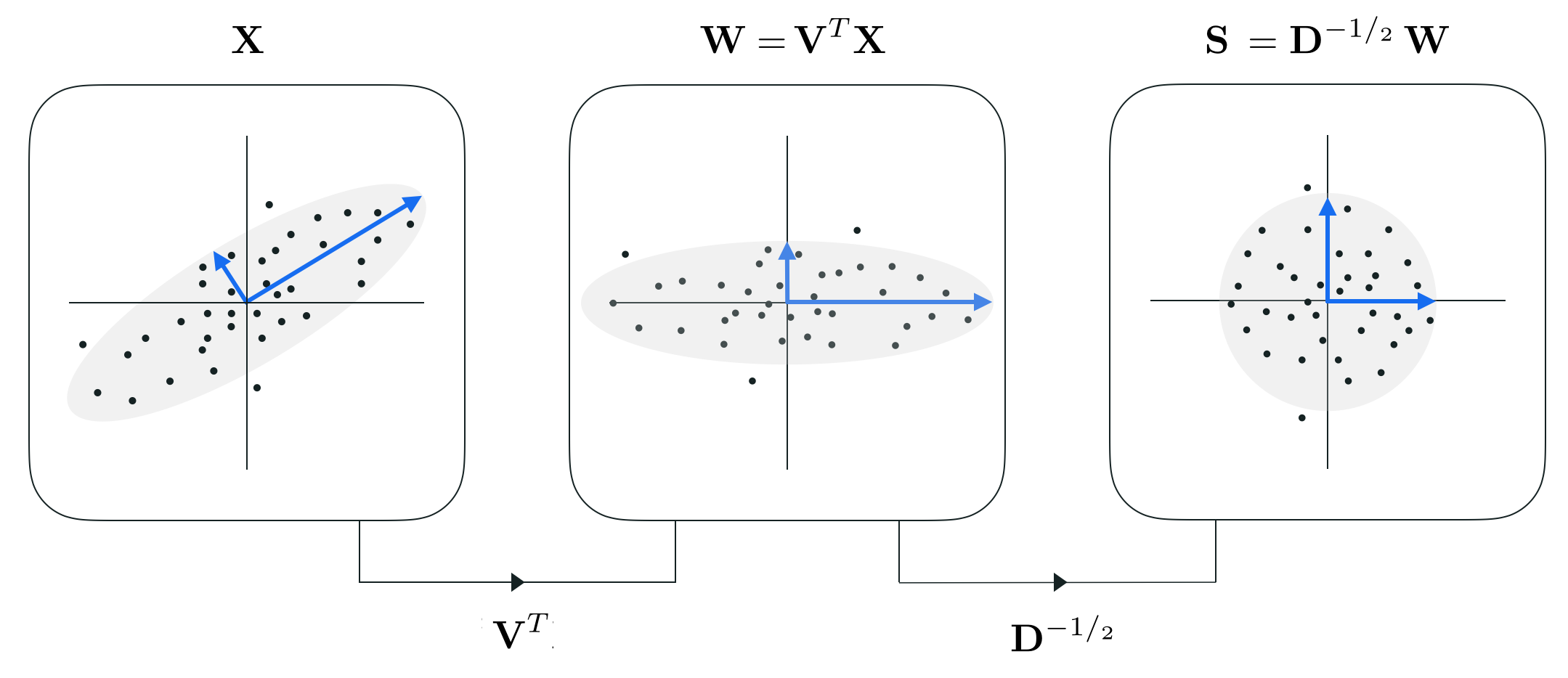
Also notice that in writing the method this way we can see how - unlike the standard normalization scheme - in performing PCA sphereing we do truly 'sphere' the data in that
\begin{equation} \frac{1}{P}\mathbf{S}^{\,}\mathbf{S}^T = \mathbf{I}_{N\times N} \end{equation}which can be easily shown by simply plugging in the definition of $\mathbf{S}$ and simplifying. This implies that the contours of any cost function we have seen thus far tend to be highly spherical, e.g., in the case of a quadratic like Least Squares for linear regression are perfectly spherical (see the analysis in Section 8.4.3 for further details), and thus will be much easier to optimize.