code

share



In this Section we formally describe the problem of linear regression, or the fitting of a representative line (or hyperplane in higher dimensions) to a set of input/output data points. Regression in general may be performed for a variety of reasons: to produce a so-called trend line (or - more generally - a curve) that can be used to help visually summarize, drive home a particular point about the data under study, or to learn a model so that precise predictions can be made regarding output values in the future.
Data for regression problems comes in the form of a set of $P$ input/output observation pairs
\begin{equation} \left(\mathbf{x}_{1},y_{1}\right),\,\left(\mathbf{x}_{2},y_{2}\right),\,...,\,\left(\mathbf{x}_{P},y_{P}\right) \end{equation}or $\left\{ \left(\mathbf{x}_{p},y_{p}\right)\right\} _{p=1}^{P}$ for short, where $\mathbf{x}_{p}$ and $y_{p}$ denote the $p^{\textrm{th}}$ input and output respectively. In simple instances the input is scalar-valued (the output will always be considered scalar-valued here), and hence the linear regression problem is geometrically speaking one of fitting a line to the associated scatter of data points in 2-dimensional space. In general however each input $\mathbf{x}_{p}$ may be a column vector of length $N$
in which case the linear regression problem is analogously one of fitting a hyperplane to a scatter of points in $N+1$ dimensional space.
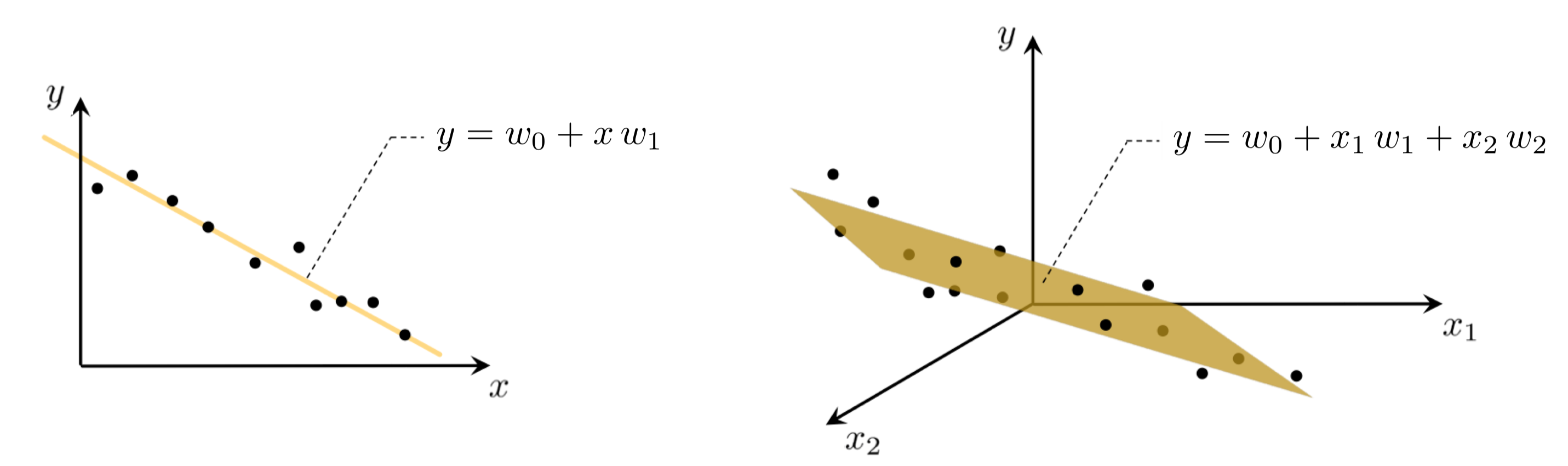
In the case of scalar input the fitting of a line to the data requires we determine a vertical intercept $w_0$ and slope $w_1$ so that the following approximate linear relationship holds between the input/output data
\begin{equation} w_{0}+x_{p}w_{1}\approx y_{p},\quad p=1,...,P. \end{equation}Notice that we have used the approximately equal sign because we cannot be sure that all data lies completely on a single line. More generally, when dealing with $N$ dimensional input we have a bias and $N$ associated slope weights to tune properly in order to fit a hyperplane, with the analogous linear relationship written as
\begin{equation} w_{0}+ x_{1,p}w_{1} + x_{2,p}w_{2} + \cdots + x_{N,p}w_{N} \approx y_{p} ,\quad p=1,...,P. \end{equation}For any $N$ we can write the above more compactly - in particular using the notation $\mathring{\mathbf{x}}_p$ to denote for $\mathbf{x}_p$ with a $1$ placed on top of it as
as
\begin{equation} \mathring{\mathbf{x}}_{p}^T\mathbf{w}^{\,} \approx \overset{\,}{y}_{p}^{\,} \quad p=1,...,P. \end{equation}The bottom $N$ elements of an input vector $\mathring{\mathbf{x}}_{p}$ are referred to as input features to a regression problem. For instance, in the GDP growth rate data described in the Example below the first element of the input feature vector might contain the feature unemployment rate (that is, the unemployment data from each country under study), the second might contain the feature education level, and so on.
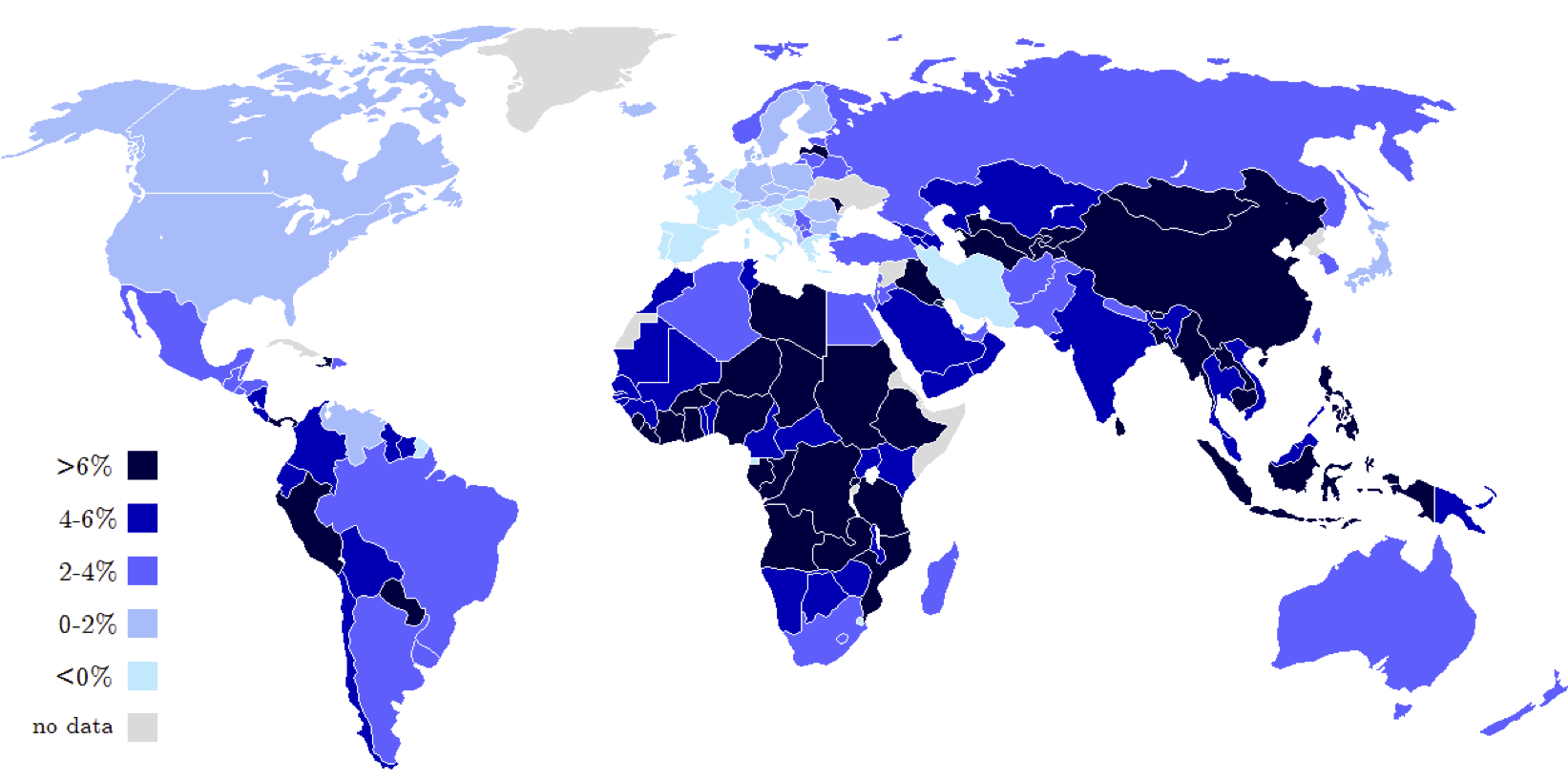
As an example of a regression problem with vector-valued input consider the problem of predicting the growth rate of a country's Gross Domestic Product (GDP), which is the value of all goods and services produced within a country during a single year. Economists are often interested in understanding factors (e.g., unemployment rate, education level, population count, land area, income level, investment rate, life expectancy, etc.,) which determine a country's GDP growth rate in order to inform better financial policy making. To understand how these various features of a country relate to its GDP growth rate economists often perform linear regression.
In the Figure below we show a heat map of the world where countries are color-coded based on their GDP growth rate in 2013, as reported by the International Monetary Fund (IMF).
To find the parameters of the hyperplane which best fits a regression dataset, it is common practice to first form the Least Squares cost function. For a given set of parameters $\mathbf{w}$ this cost function computes the total squared error between the associated hyperplane and the data (as illustrated pictorially in the Figure below), giving a good measure of how well the particular linear model fits the dataset. Naturally then the best fitting hyperplane is the one whose parameters minimize this error.
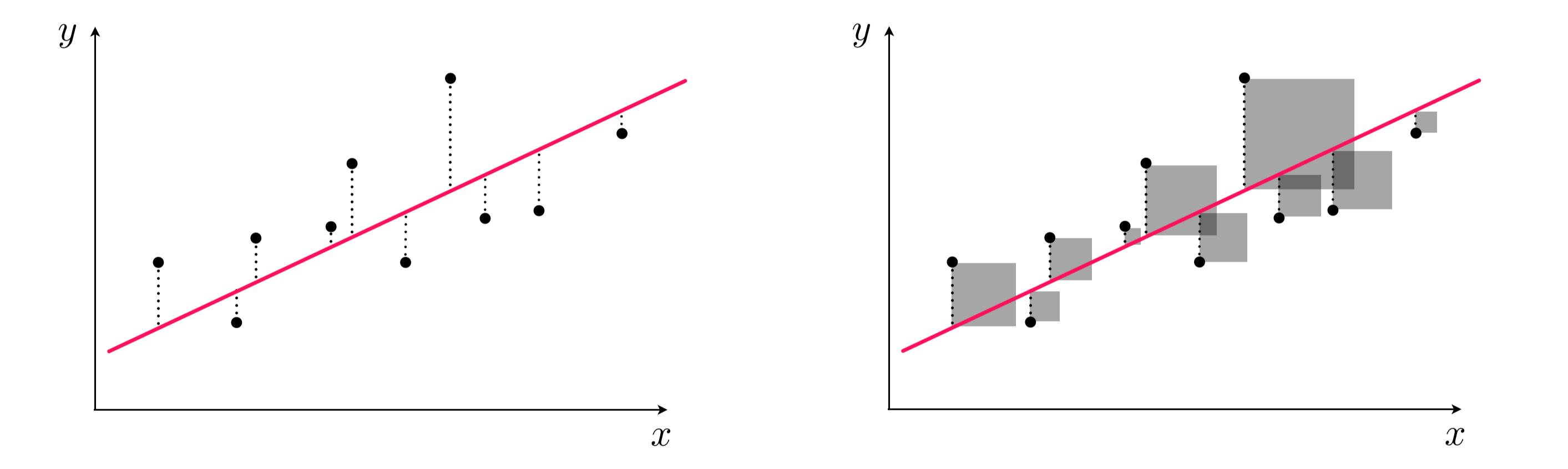
We want to find a weight vector $\mathbf{w}$ and the bias $w_0$ so that each of $P$ approximate equalities
\begin{equation} \mathring{\mathbf{x}}_{p}^T\mathbf{w}^{\,} \approx y_{p} \end{equation}holds as well as possible. Another way of stating the above is to say that the error between $w_0+\mathbf{x}_{p}^{T}\mathbf{w}$ and $y_{p}$ is small. One natural way to measure error between two quantities like this is simply to square their difference as
\begin{equation} \left(\mathring{\mathbf{x}}_{p}^{T}\mathbf{w} - \overset{\,}{y}_p^{\,}\right)^2 \end{equation}Since we want all $P$ such values to be small we can take their average - forming a Least Squares cost function
\begin{equation} \,g\left(\mathbf{w}\right)=\frac{1}{P}\sum_{p=1}^{P}\left(\mathring{\mathbf{x}}_{p}^{T}\mathbf{w}^{\,} - \overset{\,}{y}_p^{\,}\right)^{2} \end{equation}for linear regression.
We want to find parameters in $\mathbf{w}$ that provide a small value for $g\left(\mathbf{w}\right)$ since the larger this value becomes the larger the squared error between the corresponding linear model and the data, and hence the poorer we represent the given dataset using a linear model. In other words, we want to determine a value for weights $\mathbf{w}$ that minimizes $g\left(\mathbf{w}\right)$, or written formally we want to solve the unconstrained problem
Python¶When implementing a cost function like Least squares it is helpful to think modularly, with the aim lightening the amount of mental 'bookkeeping' required, breaking down the cost into a few distinct pieces. Here we can really break things down into two chunks: we have our model - a linear combination of input - and the cost (squared error) itself.
We can express our linear model - a function of our input and weights - is a function worthy enough of its own notation. We will write it as
If we were to go back then and use this modeling notation we could equally well e.g., our ideal settings of the weights in equation (7) as
\begin{equation} \text{model}\left(\mathbf{x}_p,\mathbf{w}_{\!}\right) \approx y_p \end{equation}and likewise our Least Squares cost function itself as
\begin{equation} \,g\left(\mathbf{w}\right)=\frac{1}{P}\sum_{p=1}^{P}\left(\text{model}\left(\mathbf{x}_p,\mathbf{w}\right) -y_{p}^{\,}\right)^{2}. \end{equation}This kind of simple deconstruction of the Least Squares cost lends itself to a nice, organized, and modular implementation. First we can implement the linear model like shown below.
# compute linear model of input point
def model(x_p,w):
# stack a 1 onto the top of each input
x_p = np.vstack((1,x_p))
# compute linear combination and return
a = np.dot(x_p.T,w)
return a
Then, with our linear model implemented we can easily use it to form the associated cost function like below.
# a least squares function for linear regression
def least_squares(w):
P = len(y)
cost = 0
for p in range(P):
# get pth input/output pair
x_p = x[:,p][:,np.newaxis]
y_p = y[p]
## add to current cost
cost += (model(x_p,w) - y_p)**2
# return average least squares error
return cost/float(P)
Lets reflect for a moment on this implementation. First note that in translating our 'compact' notation for the input $\mathbf{x}_p$ we explicitly stack a $1$ on top of each input at line $4$ inside the model implementation above. One could think - and rightly so - that this is very slightly wasteful since we could form each of these compact slightly adjusted input vectors beforehand (and not re-form them at each pass through the input points). This is simply a user-design choice we made to keep the name x tied to the original input data outside of the model function.
Second, we can notice that this really is a direct implementation of the algebraic form of the cost in equation (13), where we think of the cost modularly the sum of squared errors of a linear model of input against its corresponding output. However explicit for loops (including list comprehensions) written in Python are rather due to the very nature of the language (e.g., it being a dynamically typed interpreted language).
It is easy to get around most of this inefficiency by replacing explicit for loops with numerically equivalent operations performed using operations from the numpy library. numpy is an API for some very efficient vector/matrix manipulation libraries written in C. In fact Python code, employing heavy use of numpy functions, can often execute almost as fast a raw C implementation itself.
Broadly speaking, when scribing a Pythonic function with heavy use of numpy functionality one tries to package each step of computation - which previously was being formed sequentially at each data point - together for the entire dataset simultaneously. This means we do away with the explicit for loop over each of our $P$ points and make the same computations (numerically speaking) for every point simultaneously. Below we provide one such numpy heavy version of the Least Squares implementation shown previously which is far more efficient.
Note that in using these functions e expect the input x (containing the entire set of $P$ inputs) to be of size $N\times P$, and its corresponding output y to be of size $1\times P$. Also note here that we have written this code - and in particular the model function - to mirror its respective formula notationally as close as possible. However in doing so one can note that we have created another small redundancy here (in addition to tacking 1's on to our input x inside the model) - in computing the entire set of inner products we write np.dot(x.T,w) in line 8, which produces a $P\times 1$ array, and return its transpose so that the resulting array of multiplications has size $1\times P$ and matches that of y. However one could write this more simply as np.dot(w.T,x) , slightly different than it we wrote these multiplications mathematically, removing the need for an extra transpose on the return since np.dot(w.T,x) = np.dot(x.T,w).T has the correct shape.
# compute linear combination of input point
def model(x,w):
# stack a 1 onto the top of each input point all at once
o = np.ones((1,np.shape(x)[1]))
x = np.vstack((o,x))
# compute linear combination and return
a = np.dot(x.T,w)
return a.T
# an implementation of the least squares cost function for linear regression
def least_squares(w):
# compute the least squares cost
cost = np.sum((model(x,w) - y)**2)
return cost/float(np.size(y))
Now, determining the overall shape of a function - i.e., whether or not a function is convex - helps determine the appropriate optimization method(s) we can apply to efficiently determine the ideal parameters. In the case of the Least Squares cost function for linear regression it is easy to check that the cost function is always convex regardless of the dataset.
For small input dimensions (e.g., $N=1$) we can empirically verify this claim for any given dataset by simply plotting the function $g$ - as a surface and/or contour plot - as we do in the example below.
In this example we plot the contour and surface plot for the Least Squares cost function for linear regression for a toy dataset. This toy dataset consists of 50 points randomly selected off of the line $y = x$, with a small amount of Gaussian noise added to each. Notice that the data is packaged in a $\left(N+1\right)\times P$ array, with the input being in the top $N$ rows and the corresponding output is the last row.

Using the Least Squares implementation above we can evaluate any set of weights we like, as shown below
# test out a set of weights using our implementation of the N = 2 least squares function
w = np.array([0,1])[:,np.newaxis]
least_squares(w)
The contour plot and corresponding surface generated by the Least Squares cost function using this data are shown below.

In the previous example we plotted the contour/surface for the Least Squares cost function for linear regression on a specific dataset. There we saw the elliptical contours and 'upward bending' shape of the surface indeed confirms the function's convexity in that case. However the Least Squares cost function for linear regression can mathematically shown to be - in general - a convex function for any dataset (this is because one can show that it is always a convex quadratic - see Section 8.1.6 for details). Because of this we can easily apply either gradient descent or Newton's method in order to minimize it.
The Least Squares cost function for linear regression is always convex regardless of the input dataset, hence we can easily apply either gradient descent or Newton's method in order to minimize it.
The generic practical considerations associated with each method still exist here (as discussed in Chapters 6 and 7) i.e., with gradient descent we must choose a steplength scheme, and Newton's method is practically limited to cases when $N$ is of moderate value (e.g., in the thousands). For the case of gradient descent we can use a fixed steplength value (and indeed can compute a conservative Lipschitz value that will always produce descent, see Section appendix), a diminishing steplength scheme, or an adjustable method like backtracking line search.
In the next Python cell minimize the Least Squares cost using the toy dataset presented in Example 2. We use gradient descent and employ a fixed steplength value $\alpha = 0.5$ for all 75 steps until approximately reaching the minimum of the function. Here we employ the file optimizers.py which contains a short list of optimization algorithms we constructed explicitly in Chapters 5 - 7, including gradient descent and Newton's method.
Now we animate the process of gradient descent run above. The contour of the cost function is shown in the right panel with each step plotted on top, colored from green at the start of the run to red at its end (green and red points mark the initialization and final weights reached by gradient descent). As you move the slider from left to right the gradient descent process animates, until completion when the slider is all the way to the right. Simultaneously, in the left panel the corresponding linear model given by the weights at each step of gradient descent is drawn. The linear model is colored to match the step of gradient descent, so near the beginning of the run the line is green whereas near the end it is plotted red.
As can be seen while pushing the slider to the right, as the minimum of the cost function is neared, the corresponding weights provide a better and better fit to the data - with the best fit occurring at the end of the run (at the point closest to the minimum).
Whenever we use a local optimization method like gradient descent we must properly tune the steplength parameter $\alpha$. We did this for the run above by trying several fixed steplength values. Below we re-create those runs using $\alpha = 0.5$, $\alpha = 0.01$, showing the the cost function history plot for each steplength value choice. We can see from the plot that indeed the first steplength value works considerably better.
This illustrates why - in machine learning / deep learning contexts - the steplength parameter is often referred to as the learning rate, since this value does indeed determine how quickly the proper parameters of our linear regression model are learned.

As an alternative to using an Automatic Differentiator one can 'hard code' the gradient and create a gradient descent algoritihm. One can quickly compute the form of the gradient by hand (using the derivative rules detailed in Chapter 3) to be
\begin{equation} \nabla g\left(\mathbf{w}\right) = \frac{2}{P}\sum_{p=1}^{P} \mathring{\mathbf{x}}_{p}^{\,}\left(\mathring{\mathbf{x}}_{p}^{T}\mathbf{w}^{\,} - \overset{\,}{y}_p^{\,}\right) \end{equation}In this example we look at another toy dataset with $N = 2$ inputs, which is plotted by the next Python cell. This dataset consists of 50 data points taken randomly from the hyperplane $y = 1 - x_1 - x_2$ with the addition of a small amount of random Gaussian noise to their $y$ value.

In the next Python cell we minimize the Least Squares cost using the gradient descent, a constant steplength value $\alpha = 10^{-1}$ for 100 iterations beginning at the point
$$\begin{bmatrix} w_0 \\ w_1 \\ w_2 \end{bmatrix} = \begin{bmatrix} 1 \\ 1 \\ 1 \end{bmatrix}$$Now we animate this descent run. Since the linear model in this case has 3 parameters we cannot visualize each step on the contour / surface of the cost function itself, and thus must use a cost function plot (first introduced in our series on mathematical optimization) to keep visual track of the algorithm's progress.
In the left panel below we show the dataset, along with the hyperplane defined by $y = w_0 + x_1w_1 + x_2w_2$ whose weights are given at the current step in the gradient descent run. In the right panel the corresponding cost function value which plots the evaluation of each step up to the current one. Pushing the slider from left to right animates the run from start to finish - updating corresponding hyperplane in the left panel as well as cost function value in the right at each step (both of which simultaneously colored green at the start of the run, and gradually fade to red as the run ends).
As can be seen while pushing the slider to the right, as the minimum of the cost function is neared the corresponding weights provide a better and better fit to the data - with the best fit occurring at the end of the run (at the point closest to the minimum).
Once we have successfully minimized the Least Squares cost function for linear regression there are a number of ways of measuring the quality of a linear model's fit to the data. If we denote the optimal set of weights found as $\mathbf{w}^{\star}$, then we can simply compute the Least Squares error using our fully trained weights. This is often called the mean squared error (or MSE)
\begin{equation} \text{MSE}=\frac{1}{P}\sum_{p=1}^{P}\left(\mathring{\mathbf{x}}_{p}^{T}\mathbf{w}^{\star}-y_{p}^{\,}\right)^{2} \end{equation}or likewise using our model notation introduced in Section 8.1.3
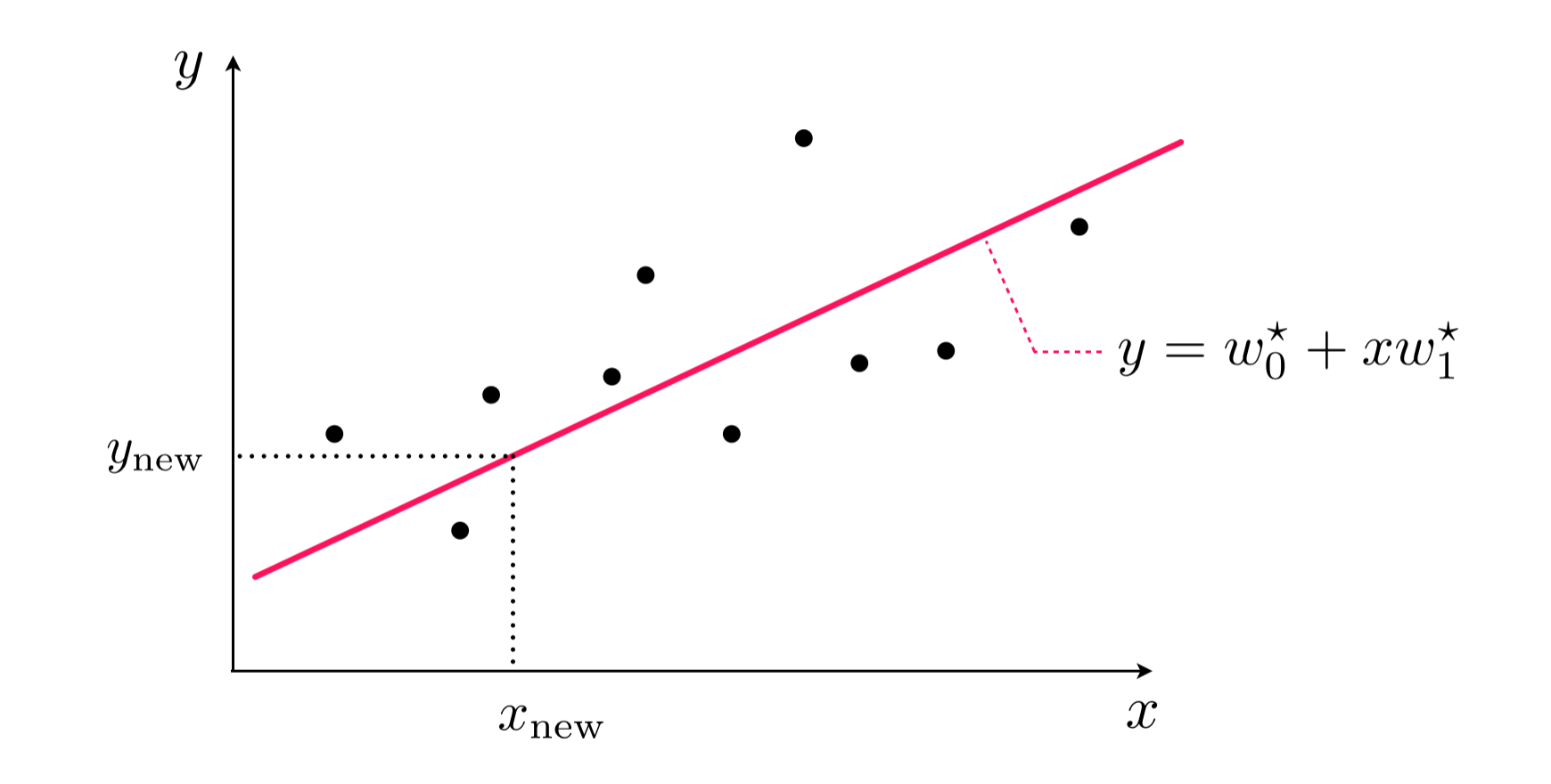
With optimal parameters $w_0^{\star}$ and $\mathbf{w}^{\star}$, found by minimizing the Least Squares cost, we can predict the output $y_{\textrm{new}}$ of a new input feature $\mathbf{x}_{\textrm{new}}$ by simply plugging the new input into the tuned linear model and estimating the associated output as
\begin{equation} \text{model}\left(\mathbf{x}_{\textrm{new}},\mathbf{w}^{\star}\right) = \mathring{\mathbf{x}}_{\textrm{new}}^{T}\mathbf{w}^{\star} = \overset{\,}{y}_{\textrm{new}}^{\,}. \end{equation}This is illustrated pictorially on a toy dataset for the case when $N=1$ in the Figure below. We can produce such a prediction using our previous model implementation.
Because the Least Squares cost function for linear regression is always a convex quadratic (see the next Subsection for a formal argument confirming this fact), we can easily use a variety of optimization techniques (e.g., coordinate and second order methods) to effectively minimize it. The application of Newton's method here is particularly interesting since - given that the function is a convex quadratic - only a single Newton step can completely minimize any Least Squares cost function for linear regression. This single-Newton-step solution is often referred to as minimizing the Least Squares cost via its normal equations.
In Example 6 of Section 7.3 we described how Newton's method perfectly minimizes any convex quadratic function in a single step since it is built on successively minimizing quadratic approximations to a given function. As we show formally in the next Subsection, the Least Squares cost function is a convex quadratic for any dataset. We show this by repeating the experiment in the previous example using a single Newton step.
The system of equations solved in taking this single Newton step is equivalent to the first order system (see Section 6.1) for the Least Squares cost function, which using the simple derivative rules described in Chapter 3 as
\begin{equation} \left(\sum_{p=1}^{P} \mathbf{x}_p^{\,}\mathbf{x}_p^T \right) \mathbf{w}_{\,}^{\,} = \sum_{p=1}^{P} \mathbf{x}_p^{\,} y_p^{\,}. \end{equation}A little re-arrangement shows that the Least Squares cost function for linear regression is always a convex quadratic, and hence is a convex function. Here we will briefly ignore the bias term $w_0$ for notational simplicity, but the same argument holds with it as well.
We can do this by first examining just the $p^{th}$ summand. By expanding (performing the squaring oepration) we have
\begin{equation} \left(\mathring{\mathbf{x}}_{p}^{T}\mathbf{w} - \overset{\,}{y}_p^{\,}\right)^2 = \left(\mathring{\mathbf{x}}_{p}^{T}\mathbf{w} - \overset{\,}{y}_p^{\,}\right)\left(\mathring{\mathbf{x}}_{p}^{T}\mathbf{w} - \overset{\,}{y}_p^{\,}\right) = \overset{\,}{y}_p^2 - 2\mathring{\mathbf{x}}_{p}^{T}\mathbf{w}\overset{\,}{y}_p + \mathring{\mathbf{x}}_{p}^{T}\mathbf{w}\mathring{\mathbf{x}}_{p}^{T}\mathbf{w} \end{equation}where we have arranged the terms in increasing order of degree.
Now - since the inner product $\mathring{\mathbf{x}}_{p}^{T}\mathbf{w} = \overset{\,}{\mathbf{w}}^T\mathring{\mathbf{x}}_{p}$ we can switch around the second inner product in the first term on the right, giving equivalently
\begin{equation} =\overset{\,}{y}_p^2 - 2\mathring{\mathbf{x}}_{p}^{T}\mathbf{w}\overset{\,}{y}_p + \overset{\,}{\mathbf{w}}^T\mathring{\mathbf{x}}_{p}^{\,}\mathring{\mathbf{x}}_{p}^{T}\mathbf{w} \end{equation}This is only the $p^{th}$ summand. Summing over all the points gives analagously
\begin{equation} \,g\left(\mathbf{w}\right)= \frac{1}{P}\sum_{p=1}^{P}\left(\overset{\,}{y}_p^2 - 2\mathring{\mathbf{x}}_{p}^{T}\mathbf{w}\overset{\,}{y}_p + \overset{\,}{\mathbf{w}}^T\mathring{\mathbf{x}}_{p}^{\,}\mathring{\mathbf{x}}_{p}^{T}\mathbf{w} \right) = \frac{1}{P}\sum_{p=1}^{P}\overset{\,}{y}_p^2 - \frac{2}{P}\sum_{p=1}^{P}\overset{\,}{y}_p^{\,}\mathring{\mathbf{x}}_{p}^{T}\mathbf{w} + \frac{1}{P}\sum_{p=1}^{P}\overset{\,}{\mathbf{w}}^T\mathring{\mathbf{x}}_{p}^{\,}\mathring{\mathbf{x}}_{p}^{T}\mathbf{w} \end{equation}And from here we can spot that indeed the Least Squares cost function is a quadratic, since denoting
\begin{array} \ a = \frac{1}{P}\sum_{p=1}^{P}\overset{\,}{y}_p^2 \\ \mathbf{b} = -\frac{2}{P}\sum_{p=1}^{P}\mathring{\mathbf{x}}_{p}^{\,}\overset{\,}{y}_p^{\,} \\ \mathbf{C} = \frac{1}{P}\sum_{p=1}^{P}\mathring{\mathbf{x}}_{p}^{\,} \mathring{\mathbf{x}}_{p}^T \end{array}we can write the Least Squares cost equivalently as
\begin{equation} g\left(\mathbf{w}\right) = a^{\,} + \mathbf{b}^T\mathbf{w}^{\,} + \mathbf{w}^T\mathbf{C}^{\,}\mathbf{w}^{\,} \end{equation}which is of course a general quadratic. But furthermore because the matrix $\mathbf{C}$ is constructed from a sum of outer product matrices it is also convex, since the eigenvalues of such a matrix are always nonnegative (see Section 7.1 and 7.2 for further details about convex quadratic functions of this form).
Since we have just seen that the cost function is convex in order to compute a Lipschitz constant we can simply compute the largest eigenvalue of the matrix $\mathbf{C} = \frac{1}{P}\sum_{p=1}^{P}\mathring{\mathbf{x}}_{p}^{\,} \mathring{\mathbf{x}}_{p}^T $. This is precisely given as the 2-norm of this matrix, squared
\begin{equation} L = \left\Vert \mathbf{C} \right\Vert_2^2 \end{equation}which one can compute via e.g., the power method.
For a larger but easier to compute Lipschitz constant one can use the trace of the matrix $\mathbf{C}$, since this equals the sum of all eigenvalues, which in this case must be larger than its maximum value since all eigenvalues are non-negative.